LongCat-2.0: Meituan Open-Sources a 1.6T Coding Model Trained Entirely on Chinese Chips
China's food-delivery giant proves frontier-scale AI training is possible without Nvidia, using 50,000 domestic ASICs to build a model now ranking top three on OpenRouter by call volume.

Meituan, China's dominant food delivery platform, open-sourced LongCat-2.0 on June 30 - a 1.6 trillion-parameter model built for agentic coding, trained entirely on 50,000 domestic Chinese ASICs. No Nvidia hardware in the stack. LongCat-2.0 scores 59.5 on SWE-bench Pro, putting it ahead of GPT-5.5 and Gemini 3.1 Pro on deep software engineering tasks, with an MIT license and a 1 million-token context window. Five days after launch, the model sat in the top three globally on OpenRouter by API call volume.
SWE-bench Pro 59.5 - Above GPT-5.5, Just Below GLM-5.2
SWE-bench Pro measures real GitHub issue resolution - actual pull-request-level changes on active repositories, not synthetic coding puzzles. LongCat-2.0's 59.5 puts it above GPT-5.5 and Claude Opus 4.6, and just below the 62.1 scored by GLM-5.2, the MIT-licensed open-weight model from Zhipu AI that launched two weeks earlier. On Terminal-Bench, which tests stable command-line execution and error recovery in real terminal environments, LongCat-2.0 scores 70.8. Developers building agentic coding pipelines now have two Chinese open-weight models scoring above GPT-5.5 on coding benchmarks. No API key required. No billing account. No usage agreement.
LongCat Sparse Attention (LSA) makes the 1M-token context practical at runtime. Attention cost in standard transformers grows quadratically with context length - doubling the context can quadruple the compute. LSA computes at linear complexity instead, which keeps the cost manageable for developers indexing large codebases or running long agent conversation histories against a local model.
50,000 Domestic ASICs - What This Proves About the Chip Controls
No Nvidia. Meituan's claim is that LongCat-2.0 completed its full training cycle on a 50,000-card cluster of domestic Chinese ASICs - no H100s, no A100s, no restricted hardware. US export controls severed Chinese companies' access to Nvidia's most powerful chips in late 2023 and have tightened since. LongCat-2.0 is the first publicly confirmed trillion-parameter model to clear that bar entirely on domestic compute.
Developers outside China access LongCat-2.0 through OpenRouter and longcat.ai - the domestic-chip constraint applies only to training, not to inference. Policymakers watching this launch will find something harder to dismiss: scale restrictions on Nvidia exports did not cap what Meituan could train. A food delivery company with deep engineering resources and domestic ASIC access just proved the export-control ceiling is lower than export-control advocates assumed. Whether other Chinese labs - with more dedicated AI infrastructure than Meituan - can push further at larger scale is the obvious next question.
MoE Architecture and the MOPD Training Approach
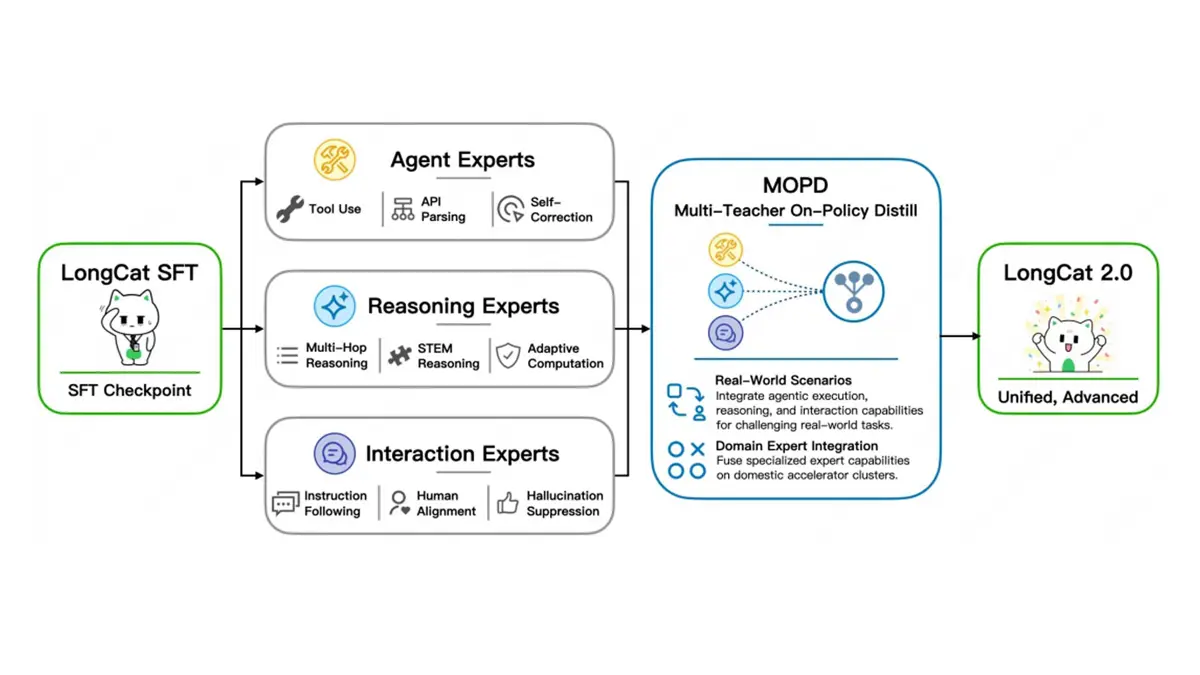
LongCat-2.0's 1.6 trillion parameters are not all active at once. Dynamic routing keeps 33B-56B parameters active per token, depending on task complexity. Zero-Computation Experts route simple tokens through near-zero-cost paths and direct complex tokens toward more parameters - which is how Meituan keeps inference costs manageable despite the trillion-parameter headline. Meituan distilled three specialist models (agentic tasks, reasoning, and interaction) into the unified final model through Multi-Teacher On-Policy Distillation (MOPD), all trained on the same domestic compute cluster used for pretraining.
A Model Family That Western Developers Mostly Missed
LongCat-2.0 is the most recent release in a research program that has been running since late 2025. Meituan's LongCat line includes Flash-Thinking (agentic search and tool use, open-source SOTA on BrowseComp), Flash-Prover (97.1% on MiniF2F-Test using Lean4 formal math verification), Flash-Lite (a 68.5B sparse MoE for lightweight inference with 256K context), Video-Avatar 1.5 (commercial-grade digital human video), and LongCat-Next, a multimodal model unifying text, image, and audio under a single autoregressive token prediction framework. All carry open-source licenses. Most Western developers encountered none of them before LongCat-2.0's benchmark results surfaced on OpenRouter this week.
Weights are on Hugging Face today. No public timeline exists for a successor model. Quarterly releases have been Meituan's pattern since late 2025 - Flash-Thinking in January, Flash-Prover in the spring, LongCat-2.0 in June. If that cadence holds, something new ships in September.