What Is a Large Language Model - and How Does It Work?
Most people interact with one daily. Almost nobody understands what actually happens when it generates a response.

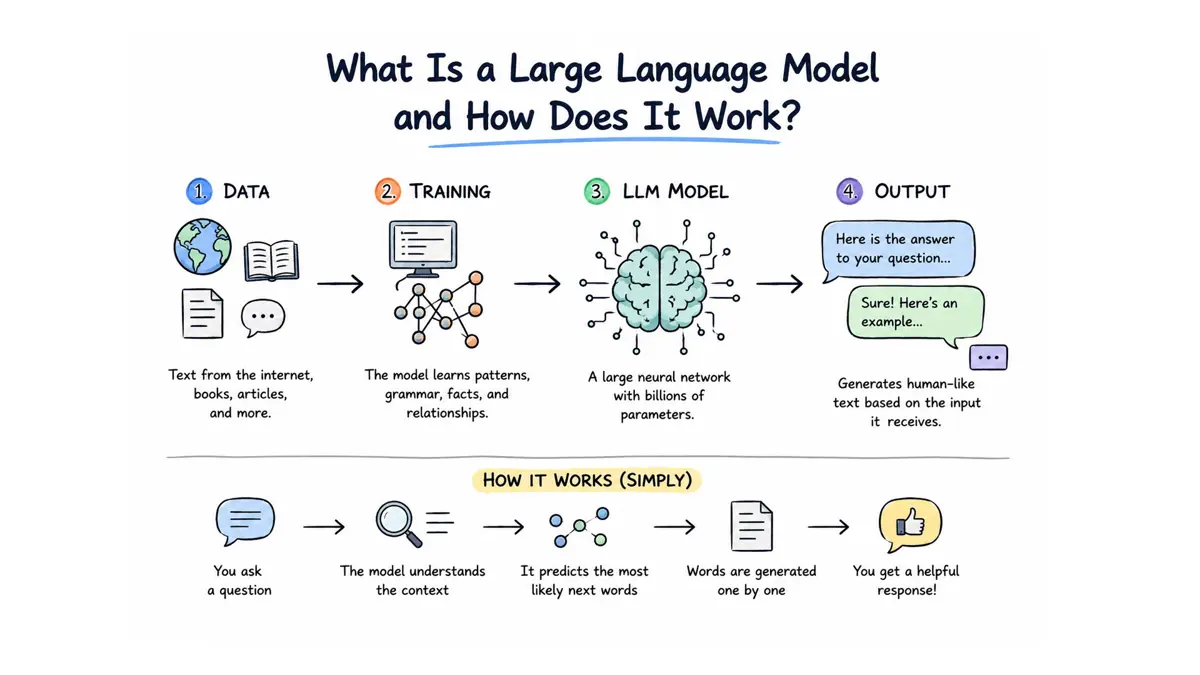
Every developer is building on top of one right now. A large language model - GPT-4, Claude, Gemini, Llama 3 - takes text as input and returns text as output. That description hides almost everything interesting about what happens between those two steps. Most confusion about what AI can and cannot do comes from a single misunderstanding: a large language model does not reason. Prediction is all it does.
LLMs Predict the Next Token - Everything Else Follows From That
Not words - tokens. A tokenizer slices English text into chunks averaging roughly three to four characters each. "Developer" typically counts as one token; "tokenization" breaks into three. GPT-4 processes up to 128,000 tokens at once, and Anthropic's Claude handles up to 200,000 - that ceiling, called the context window, determines how much text the model can consider at any given moment.
Given a sequence of tokens, an LLM calculates a probability score for every possible next token in its vocabulary, then samples from those probabilities to pick one. Repeat that operation. Do it thousands of times in sequence and you get a paragraph. Temperature - a parameter exposed in most LLM APIs - controls how much randomness enters the sampling. Low temperature produces more predictable, consistent output; high temperature produces more creative and occasionally less accurate responses.
Google researchers made this possible in 2017. Their paper, "Attention Is All You Need," introduced the transformer architecture - a design that changed how neural networks process language. Before transformers, models read text word by word, sequentially, one token at a time. Transformers replaced that with parallel processing: every token attends to every other token in the input simultaneously, which is why modern LLMs can pick up on connections between ideas separated by hundreds of lines.
Training a Large Language Model Costs More Than $100 Million
Building a large language model starts with data. Really, a lot of data. Petabytes of web text, books, GitHub repositories, Wikipedia, and academic papers form the training corpus - hundreds of billions to several trillion tokens combined. GPT-3 trained on roughly 300 billion tokens when OpenAI published it in 2020, with 175 billion parameters in the model.
Parameters are the internal numbers - weights - that training adjusts billions of times. More parameters, more capacity. GPT-4 training reportedly cost more than $100 million in compute across tens of thousands of specialized chips over many months; OpenAI has never published an official figure. Meta released Llama 3.1 in 2024 with 405 billion confirmed parameters as open weights, meaning developers can download and run the full model directly without paying per API call.
Inference - generating text at scale - costs far less than training but adds up at high volumes. Generating one response requires the entire input context to pass through the network billions of times per token produced. That cost is why AI providers charge per million tokens rather than per request, and why teams building high-traffic applications need to think about token efficiency as much as model capability.
| LLM type | Example models | Key trait |
|---|---|---|
| Closed API | GPT-4o, Claude, Gemini | Pay per token; weights never released |
| Open weights | Llama 3.1, Mistral, Phi-3 | Download and self-host; fine-tune freely |
| Specialized | Code Llama, StarCoder | Trained on code; smaller and faster per task |
Fine-Tuning Turns a Raw Text Predictor Into an Actual Assistant
A base model trained on raw internet text will complete your prompt. Answer it? Not necessarily. "Question" followed by more questions is a perfectly valid pattern in training data. Instruction fine-tuning fixes this by training the model on thousands of prompt-response pairs - a question about recursion paired with a clear explanation, repeated across domains until the model learns to answer rather than continue.
RLHF goes further. Reinforcement Learning from Human Feedback has human reviewers compare pairs of model outputs and score which response reads as more helpful, accurate, and safe. Those scores train a separate reward model, which then guides the LLM toward responses that rated well. GPT-4, Claude, and Gemini all went through variants of this pipeline - and the combination of instruction fine-tuning and RLHF explains why these models behave like assistants rather than raw text generators.
Instruction fine-tuning does not require billions of tokens. Models like GPT-3.5 were fine-tuned on a relatively small set of curated examples compared to the pre-training corpus - which is why fine-tuning an open-weights model on domain-specific data is a viable path for developers who need tailored behaviour. A legal document assistant, a coding model scoped to Python, or a support bot that only knows your product - all start with a base model and fine-tuning on top.
Most developers underestimate how much of what makes ChatGPT or Claude useful has nothing to do with the base model. Instruction tuning built the assistant. RLHF aligned it. Strip those layers away and you are left with a capable text predictor that does not behave helpfully at all - which is worth keeping in mind when evaluating model capability claims based on benchmark scores alone.
| Training stage | What happens | What it produces |
|---|---|---|
| Pre-training | Model reads trillions of tokens from web, books, and code | Base model that predicts next tokens |
| Instruction fine-tuning | Model trains on thousands of prompt-response pairs | Model that answers prompts reliably |
| RLHF | Human raters score output pairs; model learns to prefer higher-scoring responses | Aligned assistant |
Hallucinations and Context Limits Are the Constraints Developers Actually Hit
LLMs generate confident nonsense. Hallucination happens because a large language model optimises for plausible-sounding text, not verified facts. Ask about an obscure API endpoint or a paper published after the training cutoff and the model will generate something that reads correctly rather than admit it does not know. Confident wrong answers are a feature of the architecture, not a bug that a future update will simply patch away.
Hallucination is the constraint that forces architecture decisions. For any application needing factual reliability - legal research, medical summaries, live financial data - developers need retrieval-augmented generation (RAG): the model retrieves verified documents before generating a response, rather than relying on what it memorised during training. Without RAG, you are betting on the model having absorbed the right information at exactly the right level of detail - a bet that fails often enough to matter in production.
Context windows create a second ceiling. 200,000 tokens sounds generous until you feed in a full codebase, a stack of reference documentation, and three months of conversation history simultaneously. Models also lose precision when relevant information sits deep in the middle of a very long context - researchers call this the "lost in the middle" problem - where content at the start and end of a long input gets processed reliably but content buried in the centre does not.
For now, parameters help. Retrieval helps more. Pairing an LLM with a strong retrieval layer does more for factual accuracy in production than scaling up model size alone. Agentic AI systems go further by giving LLMs tools to call external APIs, run code, and verify outputs before committing to an answer - and the gap between what a raw model achieves on a benchmark and what a well-engineered system delivers in a real application is wider than most benchmark scores suggest.