Retrieval-Augmented Generation: What RAG Is and Why 51% of Enterprise AI Uses It
RAG is now the dominant pattern for enterprise AI. Here is how it turns any document collection into a grounded LLM knowledge base.

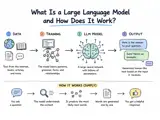
Every AI assistant built on GPT, Claude, or Gemini has the same problem: ask it about your internal documentation, last quarter's earnings, or anything published after its training cutoff and the model will either fabricate an answer or admit it does not know. Retrieval-augmented generation fixes that. A RAG system retrieves the relevant documents first, passes them to the LLM as context, and only then asks for a response. According to a Menlo Ventures 2024 survey of enterprise AI deployments, 51% now run on RAG - compared to just 9% that rely primarily on fine-tuning.
RAG Feeds the LLM Real Documents Before It Generates an Answer
Without RAG, an LLM answers entirely from memory - from patterns encoded in its weights during training. Plausible is not correct. Ask it a question and the model samples from everything it absorbed across its training corpus, producing an answer that sounds right whether or not it actually is. Hallucination is not a bug that will get patched away; it is a structural feature of how language models work.
RAG inserts a retrieval step before generation. When a user asks a question, the system searches a knowledge base for documents relevant to that specific query. The system then adds those documents to the LLM's prompt as context - before the model generates a single word of response. Grounded in real text, the model produces answers traceable to specific source documents rather than to whatever the training data happened to contain.
That traceability changes what AI can do in regulated industries. In legal, medical, and financial applications, an incorrect citation carries real consequences. RAG systems reduce hallucinations by 70-90% compared to standard LLMs according to enterprise benchmarks - though a Stanford RegLab study of production legal RAG systems published in 2024 found hallucination rates still running between 17% and 33%, which is a number worth keeping in mind before deploying RAG in high-stakes contexts without human review.
Five Steps Turn Any Document Collection Into an LLM Knowledge Base
Building a retrieval-augmented generation system means building two things in parallel: an ingestion pipeline that processes and indexes documents, and a query pipeline that retrieves the right ones at runtime. Most teams use LangChain or LlamaIndex to wire the RAG pipeline together - LangChain for broad orchestration flexibility, LlamaIndex for more opinionated document-indexing defaults.
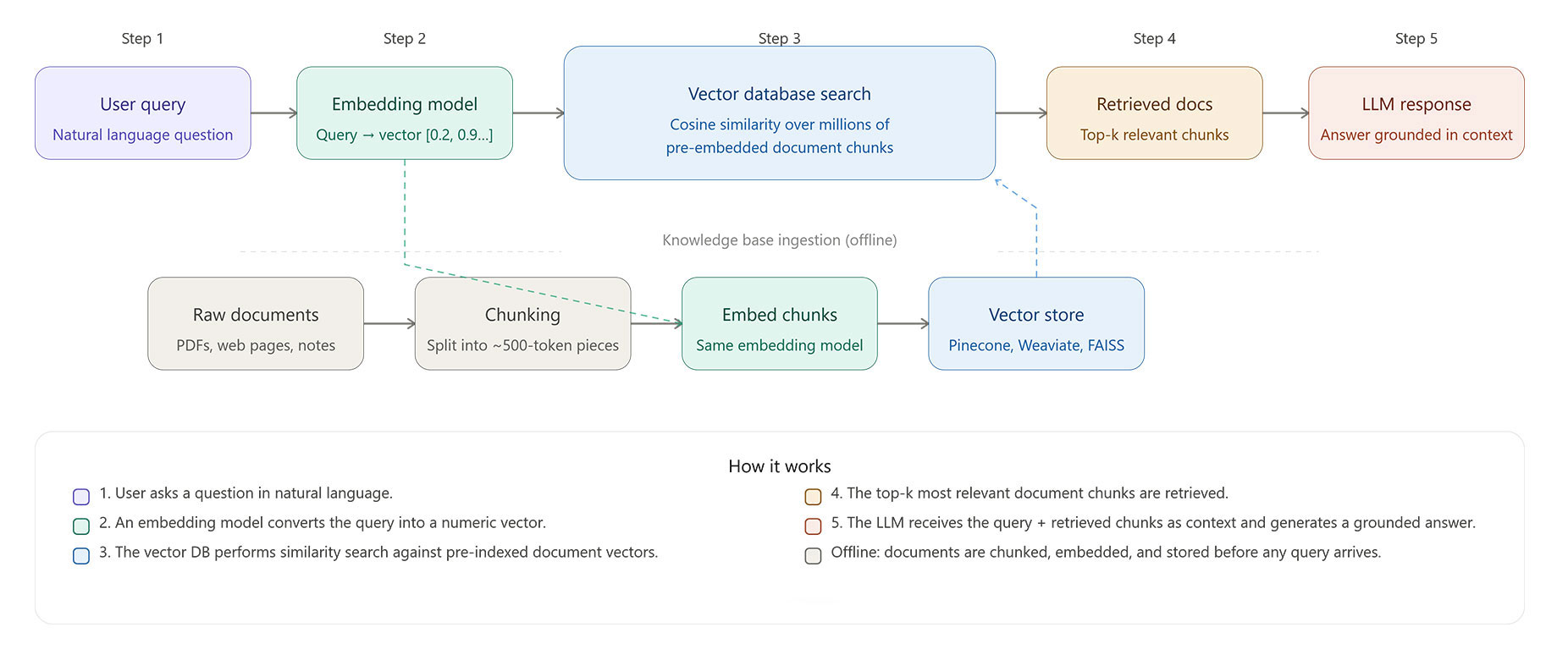
Step one is chunking. Documents do not go into the index whole - a tokenizer splits them into segments of roughly 200 to 500 words each, with slight overlap between adjacent chunks so context does not get cut off at boundaries. Fixed-size chunks work well as a baseline; a 2025 NAACL Findings paper showed that 200-word fixed chunks matched or outperformed semantic chunking on most retrieval benchmarks, which has simplified how production teams approach the initial build.
Step two is embedding. Each chunk passes through an embedding model - OpenAI's text-embedding-3-small and the open-source Sentence Transformers library are both common choices - which converts the text into a vector of 384 to 1,536 numbers that encode its meaning. Similar ideas produce similar vectors; that mathematical relationship is what makes semantic search possible.
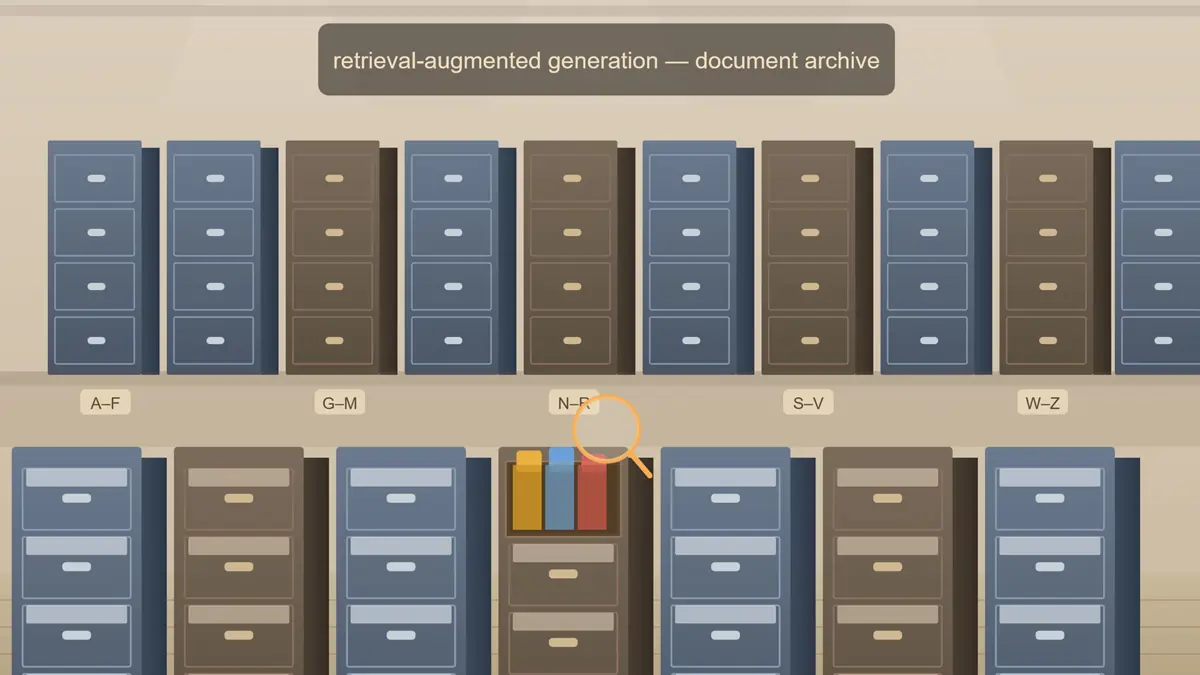
Steps three and four are storage and retrieval. Vectors go into a vector database - Pinecone, Weaviate, pgvector, and Chroma are all common in production - indexed for fast nearest-neighbour search. At query time, the user's question runs through the same embedding model, and the vector database returns the chunks whose vectors sit closest to the query vector. Closest vector means closest meaning - not just keyword overlap.
Step five is generation. Retrieved chunks go into the LLM's prompt alongside the original question, usually with an instruction to answer only from the provided text. Answers now trace back to specific source documents, and a developer can log exactly which chunks drove which parts of the response.
Fine-Tuning Teaches the Model to Behave - RAG Teaches It What to Know
Fine-tuning - retraining a model on your own data - sounds like the obvious way to make an LLM knowledgeable about your company's products, policies, and internal processes. But fine-tuning does not add new facts. Fine-tuning adjusts how a model behaves: its tone, its format, its tendency to follow certain patterns. Ask a fine-tuned model about a document it never saw during training and hallucination follows - just in your brand's voice.
RAG updates without retraining. Add a new document to the index and it becomes available for retrieval immediately - no GPU budget, no training run, no model redeploy. For enterprise teams managing knowledge bases that change daily, that operational simplicity is probably the decisive factor, more than any benchmark comparison between the two approaches.
Fine-tuning and RAG are not mutually exclusive. UC Berkeley's RAFT study found that combining retrieval with fine-tuning outperformed either approach alone across multiple benchmarks - particularly for smaller models where RAG alone leaves gaps. Production systems at scale often combine both: fine-tuning to shape response format and tone, RAG to keep factual content accurate and current.
| Approach | Best for | Key limit |
|---|---|---|
| RAG | Frequently changing knowledge, source attribution, no retraining budget | Retrieval quality determines answer quality |
| Fine-tuning | Consistent response style, domain-specific formatting, structured output | Does not add new facts; requires GPU compute |
| RAG + fine-tuning | High-accuracy systems at scale; small models needing both grounding and behaviour shaping | Most complex to build and maintain |
Retrieval Quality - Not Model Size - Determines How Well RAG Works
Bad retrieval causes most RAG failures in production. If the chunks going into the prompt do not contain the answer, no model - regardless of size - can generate a correct response from them. Garbage in, garbage out applies here more directly than anywhere else in the AI stack, which is why teams that switch to a larger LLM to fix a RAG problem often find it does not help.
Chunk size and overlap determine whether retrieval finds the right content. Chunks too small lose context; chunks too large dilute the signal and push retrieval toward superficial similarity rather than relevance. Most teams start with 200-word chunks and 20% overlap, then evaluate by measuring how often retrieved chunks actually contain the answer to a set of test queries - a process called retrieval evaluation that most teams skip and then regret.
Vector search alone misses exact matches. A contract clause that reads "Article 7.3(b)" will not surface when a user searches semantically for the same concept phrased differently. Hybrid search - combining vector similarity with BM25 keyword matching - solves this, and both LangChain and LlamaIndex enable it with a single configuration change. Most production RAG systems that have been through at least one iteration of real-world use enable hybrid search as a default.
Agentic RAG systems take retrieval further still. Rather than one fixed retrieval pass, the model decides what to retrieve, reads the results, and retrieves again if the first pass did not return enough to answer confidently. Multi-hop retrieval - where the system chains several retrieval steps to build up a complete picture - is where retrieval-augmented generation is heading for research, legal analysis, and any task that requires synthesising information across many documents rather than looking up a single fact.