
Claude Sonnet 5 vs Opus 4.8: Benchmarks, Pricing, and Which One to Run
Real benchmark data, August 31 pricing cliff, and three scenarios for deciding which model belongs in your stack.

Anthropic made Claude Sonnet 5 the default model for all plans on June 30 - no settings change, no opt-in required. Third-party benchmark data, early access partner reports, and a detailed code-review study from CodeRabbit are all in now. Claude Sonnet 5 vs Opus 4.8 is the real comparison most teams need to make: Sonnet 5 now closes enough of the capability gap to make the question serious, and it runs at less than half the flagship price. Here is what the data says about which one belongs in your stack.
Adaptive Thinking Is Now On by Default
Sonnet 4.6 ran without extended reasoning unless a developer explicitly enabled it. Sonnet 5 reasons through problems automatically and adjusts depth via a four-level effort dial: low, medium, high, and extra high. Raise effort for a long debugging session or a hard multi-file refactor. Medium effort is the right starting point for most teams - and most of Anthropic's early access partners ran there.
Sonnet 5 also rewrites its own plan mid-task. Earlier Sonnet models locked onto their first interpretation of a job and kept pushing even when reality diverged. Sonnet 5 revises its approach instead - which explains why early testers described it finishing multi-step jobs that Sonnet 4.6 abandoned. Mid-run revision is not a quirk. It is a design decision.
One detail worth tracking before migrating production pipelines: Sonnet 5 ships with a new tokenizer. Input text maps to 1.0 to 1.35 times more tokens than Sonnet 4.6, depending on content type. Watch your bills. Anthropic set introductory pricing to make the migration roughly cost-neutral, but that offset disappears when standard pricing begins September 1.
Benchmark Numbers: Near Opus, Better on Two
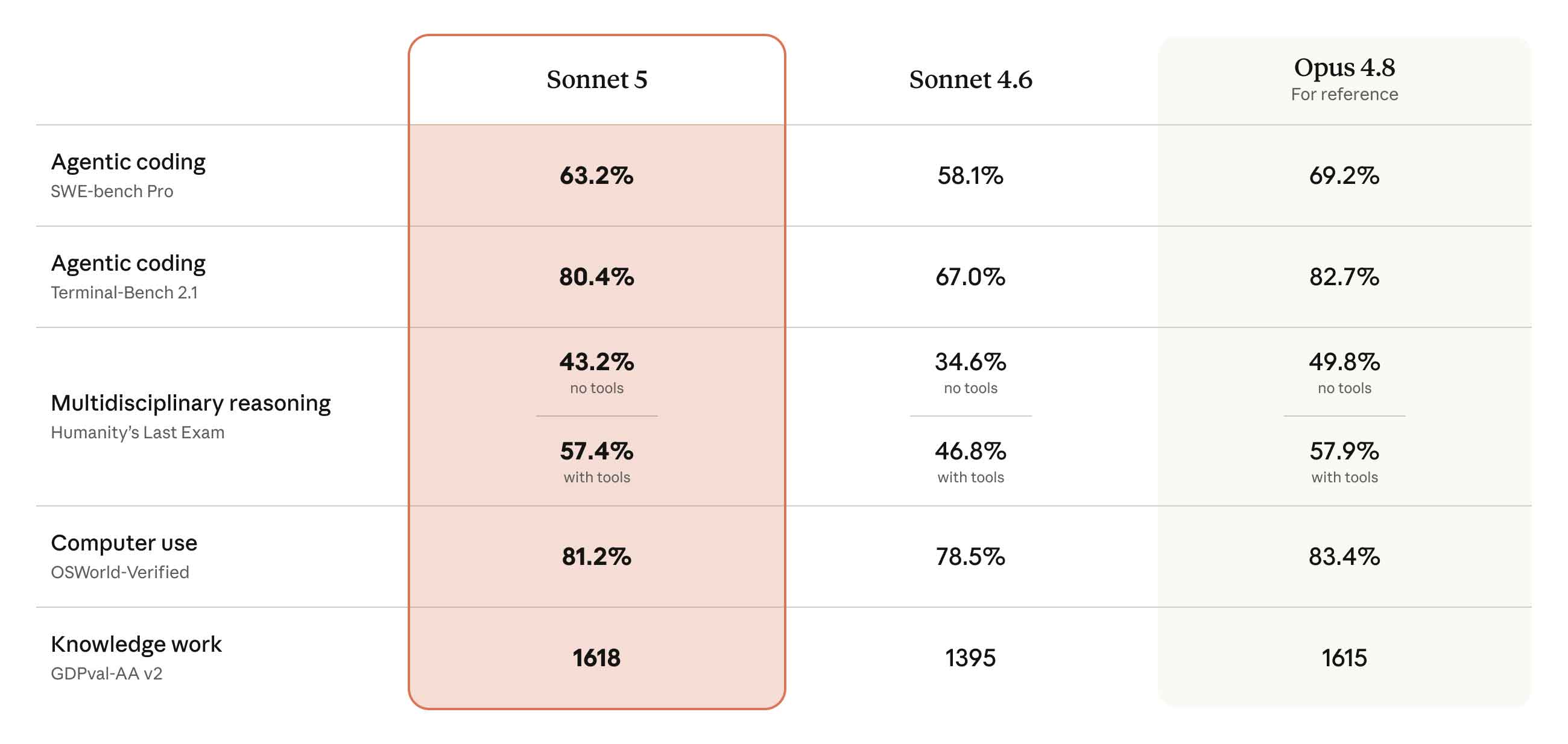
On SWE-bench Pro - the hardest agentic coding evaluation, run on real GitHub issues - Sonnet 5 scores 63.2%. Sonnet 4.6 scored 58.1% on the same test. Six points behind Opus 4.8 now, down from an 11-point gap in the previous generation. Sonnet 5 also hits 85.2% on SWE-bench Verified, a broader evaluation covering a wider set of software engineering tasks.
Two categories where Sonnet 5 outscores Opus 4.8. On Terminal-bench 2.1, Sonnet 5 scores 80.4% against Opus 4.8's 74.6% - nearly six points ahead of the flagship on a benchmark testing real terminal and command-line work. On GDPval-AA v2, a knowledge-work Elo evaluation, Sonnet 5 lands at 1,618 against Opus 4.8's 1,615. Both wins are narrow, but a Sonnet-class model beating the flagship model on any benchmark is worth calling out given the price difference.
Computer-use performance via OSWorld-Verified puts Sonnet 5 at 81.2%, up from Sonnet 4.6's 78.5%, with Opus 4.8 still ahead at 83.4%. On BrowseComp - Anthropic's agentic search evaluation - Sonnet 5 reaches 84.7%, reflecting a model that can sustain multi-step research tasks across real web environments without losing track of the goal. Not the fastest model in its class. Among the most autonomous.
What Early Access Partners Actually Found
Anthropic published partner findings alongside the launch. Neel Chotai, a Rust engineer at one partner company, reported asking Sonnet 5 to investigate a bug: unprompted, Sonnet 5 wrote a reproducing test, implemented a fix, then stashed the fix to confirm the bug returned without the change. One pass. No back-and-forth. Daniel Shepard, Senior Engineer at another partner, described a two-part Salesforce job - updating account tiers and sending a launch announcement - that used to stall halfway through. Sonnet 5 finished it end-to-end.
CodeRabbit ran Sonnet 5 through a benchmark of 470 open-source pull requests and published their findings. Precision in code review climbed from about 29% with Sonnet 4.6 to roughly 38-40% with Sonnet 5 - a higher share of comments now flags actual issues rather than noise. Bug-catching recall drops slightly: Sonnet 5 found about 50-51% of known bugs, while Sonnet 4.6 found closer to 63%. For most reviewers, that trade is the better deal - one real bug comment is worth more than five nitpicks to read through.
Lovable co-founder Fabian Hedin summarized it from a product builder's angle: "Same output quality, fewer steps to get there." Maxing the effort dial to extra high roughly doubles token spend without a proportional gain in bug-catch rate. Medium effort is the right default for most codebases. Save extra high for tasks where missing something is genuinely costly.
Pricing: $2 Now, $3 After August 31
| Model | Input per MTok | Output per MTok |
|---|---|---|
| Claude Sonnet 5 (intro, through Aug 31) | $2 | $10 |
| Claude Sonnet 5 (standard, from Sep 1) | $3 | $15 |
| Claude Opus 4.8 | $5 | $25 |
| GPT-5.4 | $2.50 | - |
| Gemini 2.5 Pro | ~$1.25 | - |
Sonnet 5 launches at $2 per million input tokens and $10 per million output tokens through August 31, 2026, then moves to $3 input and $15 output from September 1. At today's introductory rate, Sonnet 5 undercuts GPT-5.4 at $2.50/M input and sits well below Opus 4.8 at $5/$25. Gemini 2.5 Pro is cheaper per input token at roughly $1.25/M but sits at a different point on the capability curve. Price alone does not make the comparison.
Actual cost depends on the tokenizer change, and that math matters. A team consuming 100 million tokens monthly on Sonnet 4.6 might see 120 to 135 million tokens on Sonnet 5 for the same workload. At September's standard input rate of $3/M, that difference compounds fast. Introductory pricing offsets most of that increase. Standard pricing does not. Build both rate scenarios into your cost model before September.
Should You Switch? Three Cases
Switch now if you run agentic AI workflows - coding agents, automation pipelines, multi-step research jobs. Sonnet 5 finishes more autonomously, hallucinates less, and handles prompt injection attempts better than Sonnet 4.6. For teams already using Sonnet 4.6 in Claude Code or building with the Claude API, the upgrade requires no code changes. Pricing is cheaper through August. Switch now.
Run a pilot first if you operate high-volume pipelines of short, fast tasks where latency matters. Sonnet 5 is measurably slower on simple bounded work - the extra reasoning that helps on a 200-file refactor adds real overhead to a task that needed three lines fixed. Benchmark response times against your current setup before committing to a full migration.
Stay on Opus 4.8 if your work covers cybersecurity research, red-teaming, or anything that needs reduced safety guardrails. Anthropic deliberately built Sonnet 5 with weaker cyber capabilities than Opus 4.8 - Sonnet 5 cannot develop a working software exploit where Opus 4.8 can - and shipped it with real-time cyber safeguards on by default. For teams evaluating AI coding tools that include security workflows, that limitation is not a minor footnote. Opus 4.8 is Anthropic's explicit recommendation for security work.
One honest read from the data: the partners who got the most out of Sonnet 5 ran it on sustained, multi-step work at medium effort, not on quick one-off edits. Sonnet 5 earns its pricing on agent loops. Post-August, that cost goes up. Run a pilot now, measure your actual token consumption, and decide before September.