Why AI Hallucinations Happen - and What You Can Actually Do About It
LLMs do not look up facts. They predict plausible text. Understanding that gap is the first step to building systems that fail less.

AI hallucinations are not bugs waiting to be patched. Every large language model ships with the ability to generate confident, fluent, completely wrong answers - and no model update will ever eliminate that entirely. Understanding why AI hallucinations happen requires understanding what a language model is actually doing when it generates text, because the architecture that makes LLMs useful is the same architecture that makes them hallucinate.
LLMs Are Autocomplete at Scale - Not Fact Databases
Ask a language model who won the 1987 World Series and it will answer correctly. Ask it for a citation from a paper that does not exist and it will invent one - author names, journal, volume number, page range, all formatted perfectly. Both outputs use the same mechanism. Neither involves looking anything up.
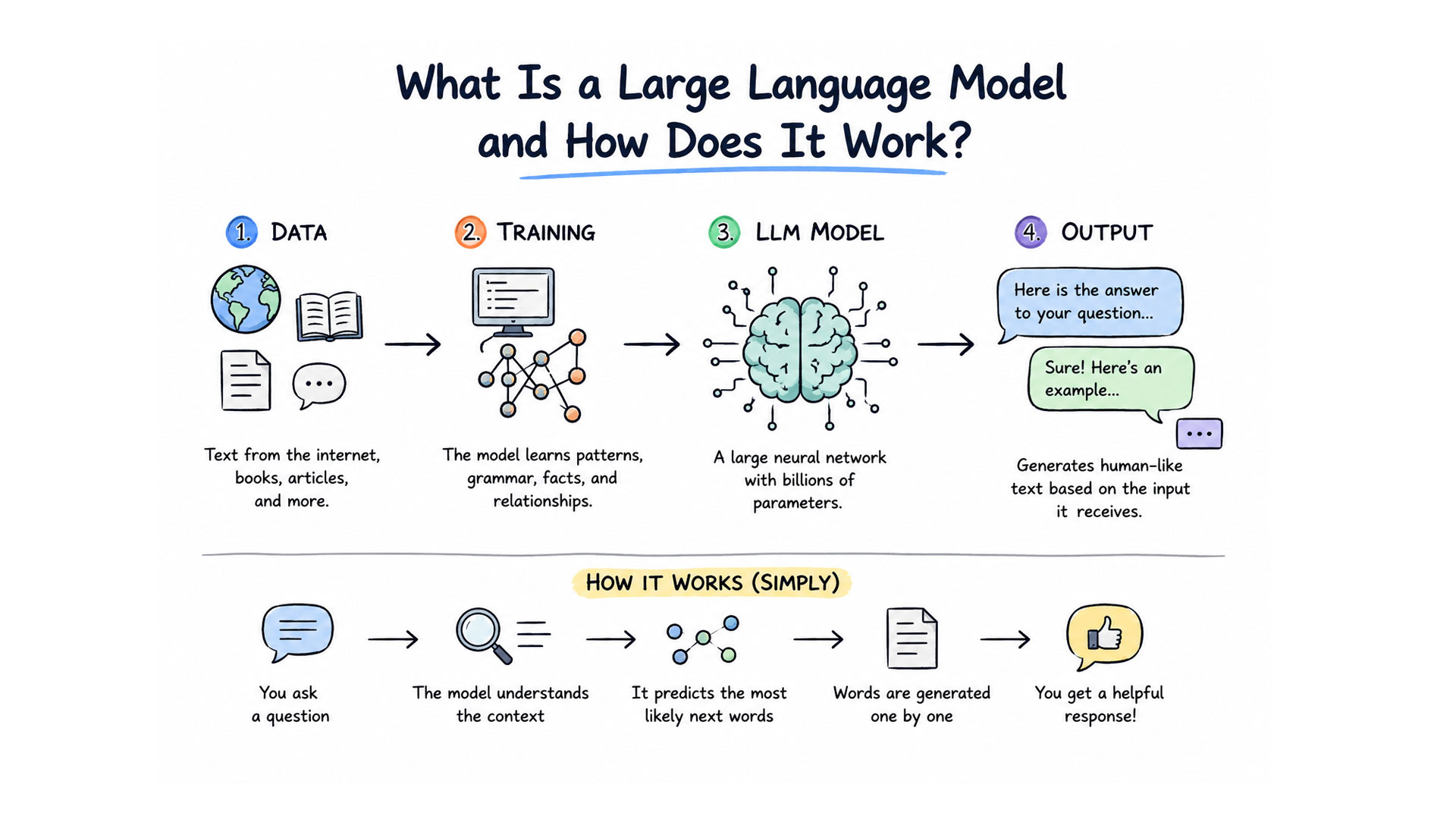
A language model is a next-token predictor. During training it processes hundreds of billions of tokens of text and learns the statistical patterns of what words follow other words across an enormous range of contexts. When you send a prompt, the model generates a response one token at a time, each token selected based on the probability distribution learned from all that training data. Factual recall is a side effect of that process - not its purpose.
Facts that appeared frequently and consistently across many training documents get encoded reliably. Obscure facts, recent events, niche technical details, and anything the training data got wrong - those get encoded poorly, or not at all. When the model reaches a token prediction where its training signal is weak, it does not stop. Stopping is not part of the architecture. Instead, it generates the most statistically plausible continuation, which looks exactly like a confident answer.
Three Structural Reasons Hallucinations Cannot Be Eliminated
No abstention mechanism. Language models are trained to generate output. A well-calibrated human expert will say "I don't know" when they don't know. A base language model has no equivalent signal. RLHF and instruction tuning reduce overconfident generation, but they push against the model's core training objective rather than replacing it. GPT-4o, Claude Opus 4.8, and Gemini Ultra all still hallucinate - the rate differs meaningfully across providers but none reaches zero. Better training reduces it. Zero is not achievable.
Weights encode distributions, not facts. A relational database stores the population of France as 68,400,000. A language model stores something more like the weighted average of every sentence about France's population it ever saw in training, compressed into billions of floating-point parameters shared across all knowledge simultaneously. Retrieval from weights is approximate by nature. A model that "knows" a fact can still fail to surface it - especially when the surrounding context is ambiguous or the fact is buried under stronger statistical signals from more common topics.
Knowledge lives in a frozen snapshot. Training ends on a specific date. Everything after that cutoff is invisible to the model unless injected at inference time. A model asked about events after its cutoff will not say "that's outside my training data" reliably - it will generate plausible-sounding content based on patterns from what came before. For developers building production applications, the knowledge cutoff is not a footnote. It is a structural constraint that requires an architectural response.
How Your Prompts and Settings Can Make It Worse
Model architecture creates the baseline hallucination risk. Prompt design and inference settings move that risk up or down significantly.
Temperature. Temperature controls how much randomness gets added to the token selection process. A temperature of 0 makes the model deterministic, always picking the highest-probability token. A temperature of 1.0 introduces substantial randomness. For creative writing, higher temperature produces more interesting output. For factual retrieval, every increase in temperature is an increase in hallucination risk. Production RAG pipelines querying internal documentation should use temperature 0 or near-0. Chatbots answering policy questions should not use the same temperature settings as marketing copy generators.
Prompt structure. Leading questions push the model toward specific answers regardless of accuracy. Asking "What did Einstein say about the Internet?" creates pressure for the model to invent a quote because the question assumes one exists. Asking "Did Einstein make any known statements about computer networks?" creates space for the model to say no. Small phrasing changes produce meaningfully different hallucination rates on identical underlying knowledge.
Context length and position. Research on long-context models shows a consistent pattern: models are less reliable at retrieving information from the middle of a long context than from the beginning or end. A 128k context window does not mean every fact inside it is equally accessible. Developers stuffing large documents into a single prompt should test retrieval accuracy across positions, not just on short contexts.
Asking for things that do not exist. Requesting citations, URLs, API endpoints, or specific document references invites hallucination because the model has learned the format of those things perfectly and can generate a plausible one on demand. Fluency and accuracy are completely decoupled here. A hallucinated research citation looks identical to a real one.
What Developers Can Actually Do About It
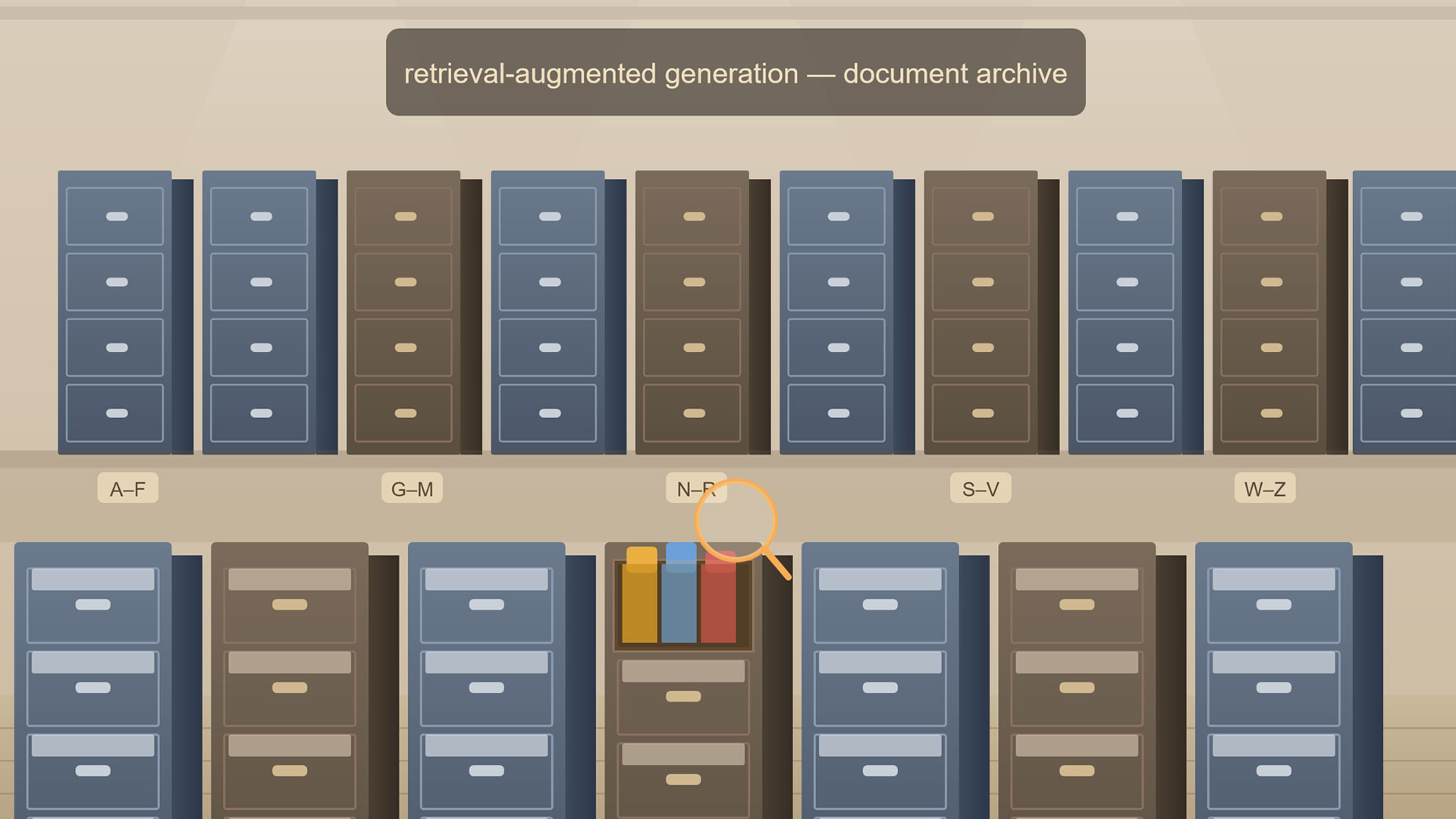
Retrieval-augmented generation. RAG is the most widely deployed mitigation because it addresses the root cause for factual tasks. Instead of asking the model to recall facts from weights, you retrieve relevant documents at query time and include them in the context window. The model's job shifts from recall to synthesis - a task it does more reliably. RAG does not eliminate hallucination (models can still misread or fabricate beyond their retrieved context) but it reduces it substantially for domain-specific factual queries.
Grounding prompts. Instruct the model explicitly: answer only from the provided context, say "I don't have that information" if the answer is not present, do not cite external sources. These instructions do not override the architecture - a determined model in an adversarial setting will still hallucinate - but they reduce casual hallucination on well-behaved inputs by setting clear expectations.
Structured outputs. Constraining the model to output JSON or another structured format with specific fields and types reduces the space of possible outputs. A model asked to return {"answer": string, "confidence": "high" | "medium" | "low", "source": string | null} has less room to invent than a model asked for free-form prose. Structured output schemas are not a complete solution but they make hallucinations more detectable - a null where a source should be is more visible than a fluent invented citation embedded in a paragraph.
Output validation layers. For high-stakes applications, treat model output as untrusted input. A separate validation step - another model call, a regex check, a database lookup, a human review gate - adds a layer between the raw generation and the user. Agentic AI architectures handle this by design: the model proposes actions, a deterministic layer validates them, and execution only follows confirmation. Anthropic's tool use and OpenAI's function calling both support that pattern natively.
Evaluation before shipping. Most production hallucination problems are discovered after deployment. Running evaluation before shipping changes that. TruthfulQA and HaluEval are public benchmarks for baseline hallucination measurement. For domain-specific applications, building a small golden dataset of questions with known correct answers and running your prompts against it is more valuable than any general benchmark. Evaluation does not need to be expensive - 50 to 100 carefully chosen questions can surface the failure modes that matter for your use case.
Build a list of 20 questions your application should answer correctly, 10 it should decline to answer, and 5 that are subtly wrong (e.g. asking for a citation you know does not exist). Run your full prompt pipeline against all 35. Any hallucination on the "should decline" or "subtly wrong" categories is a production risk. Fix the prompt before deployment, not after.
Hallucination Is a Feature of the Architecture, Not a Flaw to Be Fixed
Every developer who has been burned by a confident wrong answer has had the same instinct: this is a bug that will eventually be patched. Better models do hallucinate less - GPT-4 hallucinated more than GPT-4o, which hallucinated more than current frontier models on most benchmarks. But the improvement is incremental, not categorical.
Hallucination rates will keep falling. For production use cases where accuracy matters, zero hallucination from pure model generation is not a planning assumption developers can rely on. Grounding, validation, and evaluation are not workarounds for an immature technology. They are the architecture of any serious LLM application - for now, and for the foreseeable future.